RNL
Micro simulador 2D com matplotlib e uso de LLM para ajustar a função de recompensa de um agente (robô) durante o treinamento.
Motivação
Definir uma função de recompensa costuma exigir várias iterações: ajustar, treinar, observar o comportamento e ajustar novamente. Além disso, nem sempre é simples avaliar se uma mudança realmente melhora o resultado. Este projeto explora uma alternativa: usar um LLM (por exemplo, Gemini) para sugerir ajustes na recompensa enquanto o agente aprende.
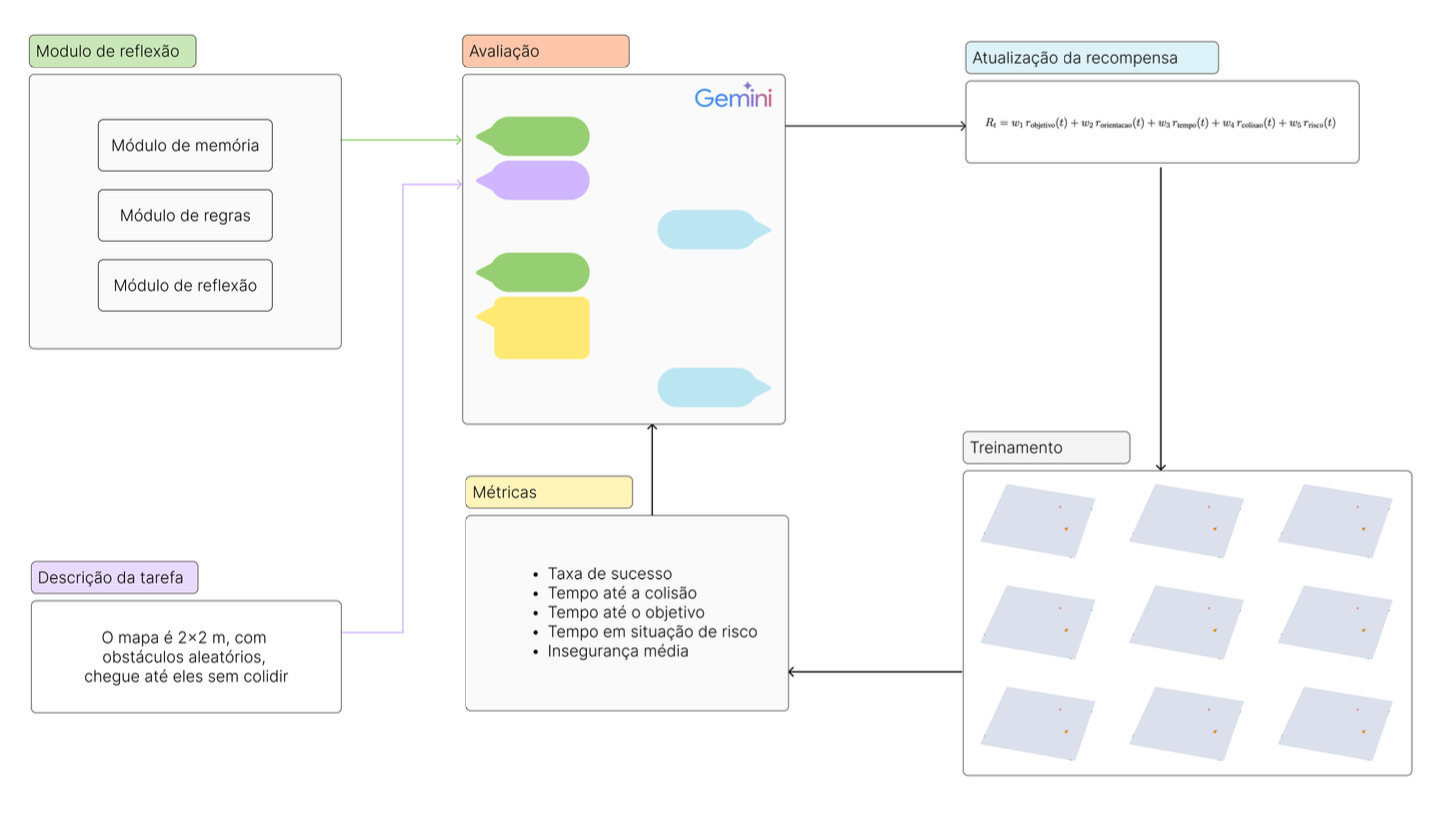
Experimento
Para manter o problema simples, optei por um cenário de navegação em 2D, onde o robô móvel diferencial precisa chegar ao objetivo sabendo apenas sua posição, a distância até o objetivo, o ângulo θ e a ação tomada anteriormente, no caso: frente, esquerda ou direita. Em vez de usar simuladores completos (Gazebo, MuJoCo), foi implementada uma simulação própria, com uma engine desenvolvida em numba básica e visualização em matplotlib.
Para treinar o robô, utilizei RL, mais precisamente o Stable Baselines (PPO). Tentei implementar o PPO do zero, mas ficou difícil evoluir a simulação e o algoritmo ao mesmo tempo. Assim, o foco permaneceu no experimento com a recompensa, e não na reimplementação do RL.
Para simplificar, o LLM não reescreve toda a recompensa. Ele ajusta apenas os pesos de módulos já definidos. Esses módulos tentam capturar requisitos comuns em navegação: chegar ao alvo, evitar obstáculos, ser eficiente e manter estabilidade.
Os módulos considerados foram:
- Orientação ao objetivo
- Distância até o alvo
- Distância até o obstáculo
- Tempo até o objetivo
- Uso da velocidade angular
def orientation_reward(alpha: float, scale_orientation: float) -> float:
alpha_norm = 1.0 - (alpha / np.pi)
if alpha_norm < 0.0:
alpha_norm = 0.0
elif alpha_norm > 1.0:
alpha_norm = 1.0
return scale_orientation * alpha_norm - scale_orientation
def prog_reward(
current_distance: float,
scale_factor: float,
) -> float:
reward = -scale_factor * current_distance
return rewarddef r3(x: float, threshold_collision: float, scale: float) -> float:
margin = 0.3
if x <= threshold_collision:
return -scale
elif x < threshold_collision + margin:
return -scale * (threshold_collision + margin - x) / margin
else:
return 0.0def time_and_collision_reward(scale_time: float = 0.01) -> float:
return -scale_timeaction_reward = 0
if action == 1 or action == 2:
action_reward = -scale_angularDiscretizei a saída do modelo para ser 0 (frente), 1 (esquerda) e 2 (direita), penalizando apenas as ações 1 e 2.
A soma dos pesos precisa ser 1.0, para normalizar o treinamento:
O objetivo é obter um comportamento que, ao mesmo tempo:
- evite colisões;
- chegue ao alvo com poucos passos (rapidez);
- não tenha oscilações excessivas (ex.: girar repetidamente);
- tenda a trajetórias curtas, mas com margem de segurança.
Modelo LLM
Utilizei a API do Gemini por ser gratuita. A ideia consiste em um ciclo de treinamento → avaliação → modificação dos pesos → reinício do treinamento. O prompt utilizado nos testes foi:
You are a reward engineer. Analyze the current training metrics and propose improvements to the reward function to optimize agent performance.
...
### Reflection:Resultados
Esta é uma visualização breve apenas para observar a saída do LLM.
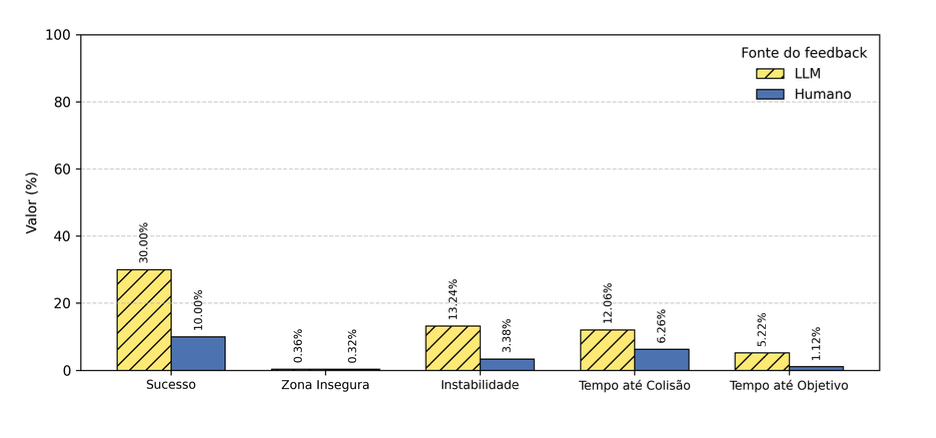
Mesmo executando vários testes, percebi que o Gemini consegue otimizar apenas um único objetivo por vez. Quando tenta melhorar outras funções, acaba perdendo o que já havia sido otimizado.
Após o treinamento, o executei o modelo no Turtlebot:
Aqui o robô está 100% usando o modelo treinado nesse simulador com ajuste do LLM. Ele apenas precisa chegar aos objetivos em X, em preto.